Извлечение структуры сайта с использованием хлебных крошек
Содержание
скрыть
Хлебные крошки на сайте часто отображают иерархию категорий и разделов. Извлекая эти данные, можно восстановить структуру сайта, даже если URL-структура не иерархическая.
Шаг 1: Откройте страницу с хлебными крошками
- Найдите страницу на сайте, которая имеет четко структурированные хлебные крошки. Обычно они находятся в верхней части страницы или в ее начале.
- Например, хлебные крошки могут выглядеть как навигация типа: Главная > Каталог услуг > Услуга.

Шаг 2: Анализ HTML-кода страницы
- Перейдите на нужную страницу и нажмите правой кнопкой мыши на хлебные крошки.
- Выберите Inspect или Посмотреть код (зависит от браузера), чтобы открыть инструменты разработчика.
Шаг 3: Найдите элемент хлебных крошек
- В панели инструментов разработчика найдите элемент, который соответствует хлебным крошкам. Он обычно представлен как тег <div>, <nav>, или <ul>.
- Например, может быть тег, который содержит список ссылок, разделенных стрелками или другими символами.
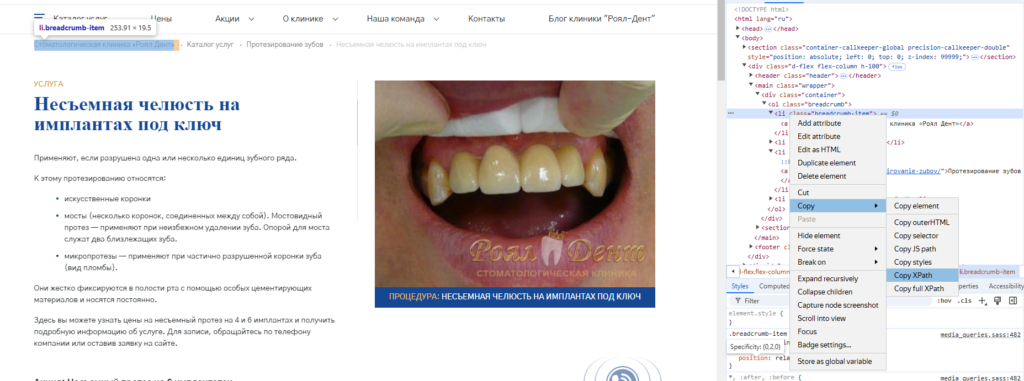
Шаг 4: Копирование XPath
- Щелкните правой кнопкой на нужном элементе в коде HTML и выберите Copy > Copy XPath. Это скопирует путь к элементу в формате XPath, который будет использоваться для извлечения данных в Screaming Frog.
Шаг 5: Настройка Screaming Frog для извлечения данных
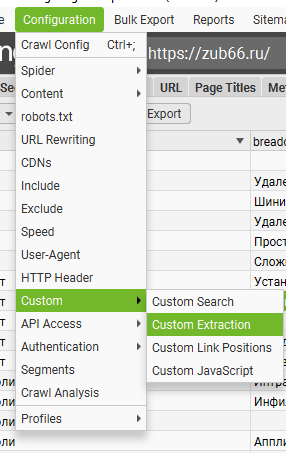
- Вернитесь в Screaming Frog и перейдите в меню Configuration > Custom Extraction.
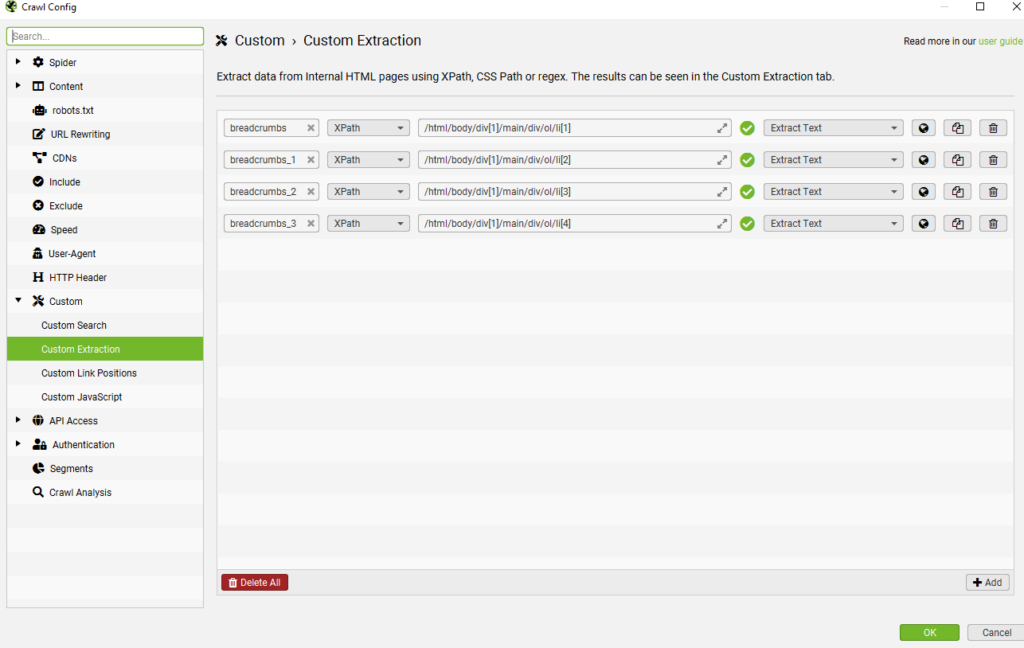
- В открывшемся окне нажмите Add Extraction и выберите XPath.
- Вставьте скопированный XPath в поле XPath.
- Убедитесь, что установлено правильное значение Extraction Type (обычно Extract Text, чтобы получить текст из хлебных крошек).
- Нажмите OK, чтобы сохранить настройку.
Шаг 6: Запуск парсинга с извлечением данных
- Вернитесь в основной интерфейс Screaming Frog и снова запустите сбор данных (кнопка Start).
- Теперь программа будет собирать не только стандартную информацию о страницах, но и данные, которые вы указали для извлечения, например, хлебные крошки.
1. Обработка данных
- После завершения сканирования вы увидите список собранных страниц в программе.
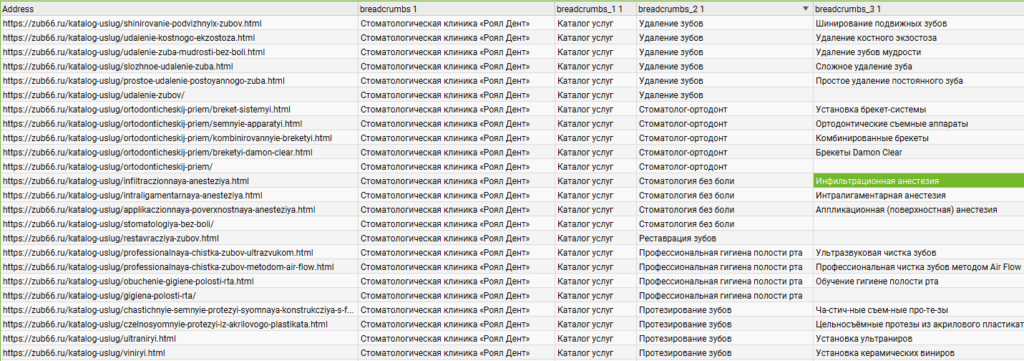
- Перейдите на вкладку Custom в нижней части интерфейса, чтобы увидеть результаты извлечения.
- В этой вкладке будут отображаться данные, извлеченные по вашему XPath, например, текст хлебных крошек.
2. Экспорт данных
- Чтобы использовать собранные данные, экспортируйте их в формат Excel или CSV.
- Для этого перейдите в меню File > Export.
- Выберите формат, например, CSV или Excel и сохраните файл на своем компьютере.
3. Редактирование и анализ структуры
- Откройте экспортированные данные в Excel или Google Sheets.
- Используйте полученную информацию для анализа и восстановления структуры сайта.
- Вы можете видеть, какие разделы сайта в каком порядке расположены.
- На основе данных можно объединить разделы, добавить новые или изменить существующие.
4. Дополнительные настройки и улучшения
- В случае, если структура сайта сложная или динамическая (например, уникальные ID для каждого элемента), вам может понадобиться настроить более сложные XPath или CSS-селекторы для точного извлечения данных.
- Также Screaming Frog позволяет собирать и другие элементы, такие как заголовки страниц (H1), метатеги, ссылки и изображения. Это можно настроить в разделе Configuration > Custom Extraction, используя аналогичный подход.
5. Применение полученных данных
- После того как вы восстановите структуру с помощью Screaming Frog, используйте полученную информацию для:
- Проектирования структуры нового сайта или доработки структуры существующего.
- Изучения конкурентов и их структуры для улучшения SEO.
- Оптимизации сайта для лучшей индексации и навигации.